

| 行政中心: | 广州市天河区黄埔大道中662号金融城绿地中心2008室 |
| 开发中心: | 广州市天河区软件园禾田大厦326室 |
| 邮 编: | 510665 |
| 电 话: | 020-83628993 |
| 传 真: | 020-83628992 |
数据库性能监控
典型的应用场景
 Surveillance 可以帮助运维人员轻松完成对跨地域的多个服务器,以及多种数据库平台,进行统一的主动式监控。
Surveillance 可以帮助运维人员轻松完成对跨地域的多个服务器,以及多种数据库平台,进行统一的主动式监控。
 如果某台 机器异常,管理员将得到警报信号(短信,弹出窗口,电邮,HP Openview、IBM Tivoli等方式),甚至,
如果某台 机器异常,管理员将得到警报信号(短信,弹出窗口,电邮,HP Openview、IBM Tivoli等方式),甚至,
如果过一段时间无人响应, Surveillance可以调用一些预先编译好的外部脚本或程序来自动处理一些可预见的异常,
保证在客户发现问题之前就可以发现问题并解决问 题。
 Surveillance 提供了一整套的图形化显示界面,帮助用户自上而下地了解系统状态。警告提示还能引导运维人员逐
Surveillance 提供了一整套的图形化显示界面,帮助用户自上而下地了解系统状态。警告提示还能引导运维人员逐
步打开相应的图形窗口 ,深入到问题的根源去发现问题解决问题,而不用运维人员去记忆众多的脚本,有助于新人快
速上手工作。
 Surveillance 利用记录的历史数据还原故障发生时的现场,从而运维人员可以回溯定位历史故障原因,彻底解决隐
Surveillance 利用记录的历史数据还原故障发生时的现场,从而运维人员可以回溯定位历史故障原因,彻底解决隐
患。此外,历史数据还 能基于宏观的角度,以丰富的报表形式,真实地展现系统的运行情况,以供趋势分析和运维
决策。
事件管理
 提供关键 度量参数的无人值守监控
提供关键 度量参数的无人值守监控
 依靠分析 引擎,设定的规则被不断的分析,以确定参数没有超过阈值设定
依靠分析 引擎,设定的规则被不断的分析,以确定参数没有超过阈值设定
 依靠警告 引擎,可以在事件发生时,以及事件已经被解决时发出提示或警报
依靠警告 引擎,可以在事件发生时,以及事件已经被解决时发出提示或警报
 改变以往 运维部门通常事后处理的工作流程
改变以往 运维部门通常事后处理的工作流程
事件管理-规则分析引擎
 基于规则 机制,预定义了一整套规则,且每条规则都可定义更为灵活的参数以控制事件的产生
基于规则 机制,预定义了一整套规则,且每条规则都可定义更为灵活的参数以控制事件的产生
 用户可自 定义新的规则
用户可自 定义新的规则
 引擎独立运 行
引擎独立运 行

案例场景分析
案例场景一
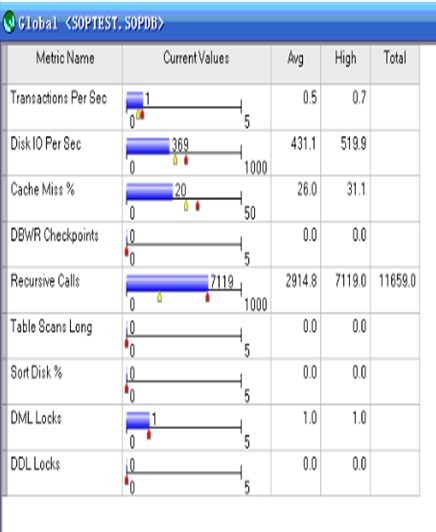
 Cache Miss %该指标实时值竟然达到20%,平均值更高达26%,一般这个值不大于5%为佳,超过则说明数据在内 存中重
Cache Miss %该指标实时值竟然达到20%,平均值更高达26%,一般这个值不大于5%为佳,超过则说明数据在内 存中重
复使用率下降,导致要频繁进 行磁盘交互到文件系统查找数据。。
 一个cache miss在shared pool(共享池)中发生比在data buffer中发生导致的成本更高,由于dictionary数据一般比
一个cache miss在shared pool(共享池)中发生比在data buffer中发生导致的成本更高,由于dictionary数据一般比
librarycache(库缓存)中的 数据在内存中保存的时间长,所以关键是library cache的优化。
 Recursive calls(数据字典的访问回调)太多,不应超过seesion数的4倍。
Recursive calls(数据字典的访问回调)太多,不应超过seesion数的4倍。
案例场景二
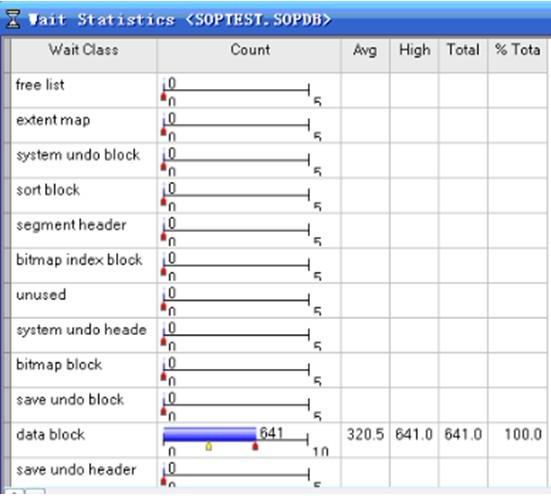
 在 Wait Statistics的窗口里,Segment header与Data Block的wait指标值比较值得关注。
在 Wait Statistics的窗口里,Segment header与Data Block的wait指标值比较值得关注。
 Data Block总的wait比率达到100%,非常严重;如果数据块一直处于等待的状态,则导致整个数据库的访问效率。
Data Block总的wait比率达到100%,非常严重;如果数据块一直处于等待的状态,则导致整个数据库的访问效率。
调大init.ora 参数 FREE_LIST_PROC 解决data block问题。
案例场景三
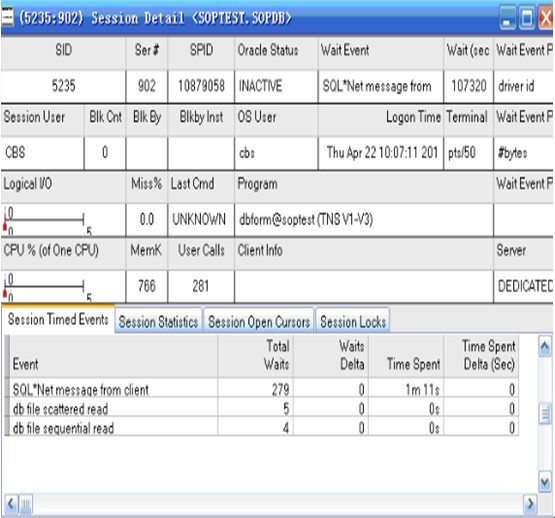
 这些是Oracle Library Cache里的一些指标,Get Miss Percent是查找对象的命中率,Pin Miss Percent是读取
这些是Oracle Library Cache里的一些指标,Get Miss Percent是查找对象的命中率,Pin Miss Percent是读取
或执行对象的命中率,Reload 是SQL重新解析的次数。
 测 结果表明,SQL AREA中这些指标的值都比较高,导致查询性能下降,解决方法可以通过一方面检查应用
测 结果表明,SQL AREA中这些指标的值都比较高,导致查询性能下降,解决方法可以通过一方面检查应用
代码,提高应用代码的效率,一方 面可以通过增加参数shared_pool_size的值。

案例场景四
 该 指标反映测试数据库的SQL存在很大的性能调优问题。可以通过单击某个指标,对该指标下的所有值进行
该 指标反映测试数据库的SQL存在很大的性能调优问题。可以通过单击某个指标,对该指标下的所有值进行
排序,通过比较,查看SQL总的占用 资源情况
 通 过向下钻取功能可以发现每一条SQL现在和历史发生时占用资源和冲突的情况,从而可以预警开发者如何
通 过向下钻取功能可以发现每一条SQL现在和历史发生时占用资源和冲突的情况,从而可以预警开发者如何
提高SQL的优化能力。
案例场景五
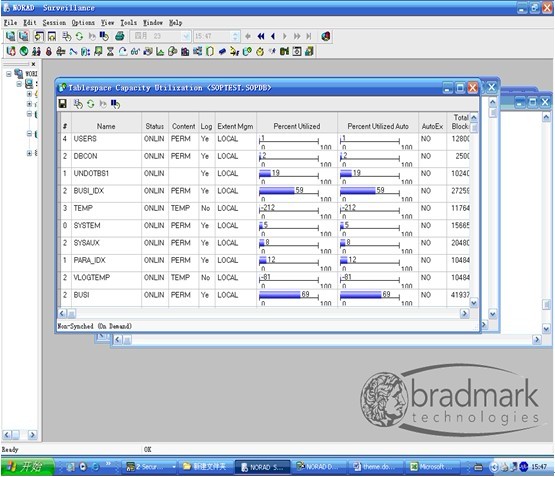
 数据库的Tablespace设计不合理。
数据库的Tablespace设计不合理。
 没有一个Tablespace是AntoEx,有些表空间的使用率已达到70%,当Percent Utilized达到或接近100%时的
没有一个Tablespace是AntoEx,有些表空间的使用率已达到70%,当Percent Utilized达到或接近100%时的
隐患很大,可能会因为分配数据区 域失败而终止应用。
更多的数据库性能监控的范围和指标
